
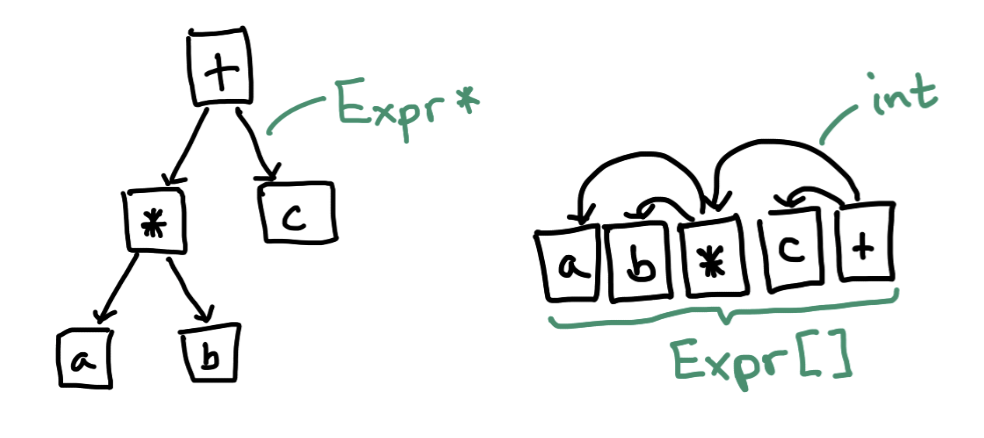
I wrote that blog post I threatened a while back about “flattened” ASTs. I did a little microbenchmarking of a toy interpreter and the results were surprisingly good?? https://www.cs.cornell.edu/~asampson/blog/flattening.html

@adrian beyond the advantages you mentioned, what do you think about the potential for speeding up compilers by organizing their data in tabular fashion so that it can be processed using tensor hardware?
@adrian large parts of optimizing compilers are performing highly parallelizable fixpoint iterations; single-threading that stuff seems just silly
@regehr yeah, I don't want to overstate the case, but it does seem like different (and denser) data structures are at least the first step toward using very different-looking parallel algorithms

{kind=link}
@adrian @regehr if you haven't already, it's probably worth reading the HPC literature on implementing Barnes-Hut style tree approximations on GPU. There are some pretty neat tricks in, for example, https://arxiv.org/pdf/1106.1900.pdf

@elfprince13 yeah, I think a lesson here is that the performance trade-offs involved are somewhat incomparable, so you have to measure the bottom line